
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Spring MVC 동작원리
- 클라우드에서 도커 실행하기
- 자바
- OOP
- vm인스턴스생성
- 알고리즘
- 코딩테스트
- 성능테스트툴
- 코드스테이츠 백엔드
- 프로그래머스
- 버블정렬
- java
- Spring Web MVC
- 재귀함수
- List.of
- 구간합구하기
- MySQL
- 스택
- 코드스테이츠
- 싱글톤패턴
- 11659
- Spring MVC 구성요소
- 투포인터알고리즘
- GCP
- String.valueOf()
- 인텔리제이
- 백준
- Array.asList
- 재귀와반복문
- 백준 11659
- Today
- Total
목록글 전체 보기 (242)
순간을 기록으로
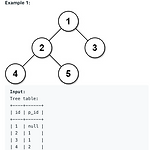 [LeetCode] Tree Node
[LeetCode] Tree Node
문제 Tree 테이블을 이용해서 Output 테이블처럼 루트 노트면 'Root', Inner 노드면 'Inner', 잎노드이면 'Leaf'을 값으로 갖는 테이블을 만들어야하는 문제. 처음엔 못풀었다가 솔루션을 보고 풀었다. id와 p_id 관계를 이용해서 문제를 풀 수 있다. 만약 루트 노드는 부모 노드가 없으므로 p_id가 null이면 루트 노드다. 그리고 id 값에 해당하는 p_id가 있으면 해당 노드는 Inner 노드다. 그 외에는 모두 Leaf 노드에 해당한다. 풀이 1 2 3 4 5 6 7 8 SELECT id, CASE WHEN p_id is null then 'Root' WHEN id in (select p_id from tree) then 'Inner' else 'Leaf' END AS '..
 [LeetCode] Employees With Missing Information
[LeetCode] Employees With Missing Information
문제 풀이 이 문제에서는 이름이 없거나 봉급이 없는 직원의 employee_id를 조회해야 하므로 AUB 에서 교집합을 제외한 데이터를 찾는 문제다. 참고로 Oracle에서는 full join을 지원하지만 MYSQL에서는 Full Join을 지원하지 않기 때문에 LEFT JOIN과 UNION을 이용해서 문제를 풀어야 한다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 SELECT e.employee_id FROM Employees e LEFT JOIN Salaries s ON e.employee_id = s.employee_id where salary is null UNION SELECT s.employee_id FROM Salaries s LEFT JOIN Employees e ON s...
 [LeetCode] Rearrange Products Table
[LeetCode] Rearrange Products Table
문제 풀이 select구에 문자열을 입력해서 속성 값을 설정할 수 있는 것이 포인트였던 문제. 1 2 3 4 5 6 7 8 9 10 11 12 13 select product_id, 'store1' as store, store1 as price from products where store1 is not null union select product_id, 'store2' as store, store2 as price from products where store2 is not null union select product_id, 'store3' as store, store3 as price from products where store3 is not null; Colored by Color Script..
 [LeetCode] Two Sum
[LeetCode] Two Sum
문제 풀이 1: 완저탐색 완전탐색으로 문제를 풀 수 있지만 효율적이지 못하다. 데이터의 크기는 10000이고 완전탐색의 경우 O(n^2)이므로 아슬아슬하게 통과한다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import java.util.HashMap; import java.util.Map; public class Solution { public int[] twoSum(int[] nums, int target) { int[] result = new int[2]; for (int i=0; i
 [LeetCode] Patients With a Condition
[LeetCode] Patients With a Condition
문제 풀이 이 문제도 한번에 풀지 못했다. 처음에 conditions like '%DIAB1%'으로 시도했는데 틀렸다. 왜냐면 'PREDIAB1'처럼 앞에 문자가 붙을 경우는 제외되어야 하는데 포함되기 때문이다. 따라서 다음과 같이 작성해야 한다. 1 2 3 4 select * from patients where conditions like 'DIAB1%' or conditions like '% DIAB1%'; cs
 [LeetCode] Group Sold Products By The Date
[LeetCode] Group Sold Products By The Date
문제 풀이 마지막 products 열에서 제품 이름을 한 셀안에 넣는것이 핵심이있던 문제다. 결국 솔루션을 먼저 봤지만 빠르게 보길 잘했다. CONCAT_GROUP(속성)이라는 함수를 알고 있어야 했다. 위 함수를 사용하면 서로다른 결과 행을 한 셀안에 표현할 수 있다. 기본적으로 구분자는 ','로 설정되어있다. 구분자를 변경하려면 SEPARATOR '구분자'를 추가로 넣어주면 된다. 1 2 3 4 5 6 7 SELECT sell_date, COUNT(DISTINCT product) as num_sold, GROUP_CONCAT(DISTINCT product ORDER BY product) as products FROM Activities GROUP BY sell_date ORDER BY sell_dat..
 [LeetCode] Fix Names in a Table
[LeetCode] Fix Names in a Table
문제 풀이 name 속성의 값을 첫 문자는 대문자로 나머지 문자는 소문자로 수정하는 SQL을 작성해야 한다.그리고 결과는 user_id를 기준으로 오름차순 정렬을 해야한다. mysql에서 제공하는 여러 함수들을 이용해서 결과를 구할 수 있다. 문제를 풀기 위해 사용할 함수는 다음과 같다. CONCAT(A,B): A,B 문자열을 연결한 문자열을 반환하는 함수 UPPER(A): 영어 문자열 A를 대문자로 구성된 문자열로 반환하는 함수 LOWER(A): 영어 문자열 A를 소문자로구성된 문자열로 반환하는 함수 LEFT(A,N): 문자열 A를 왼쪽부터 길이가 N만큼의 substring을 반환하는 함수 RIGHT(A,N):문자열 B를 오른쪽부터 길이가 N만큼의 substirng을 반환하는 함수 1 2 3 selec..
 [Java] 백준_카드 정렬하기_1715
[Java] 백준_카드 정렬하기_1715
문제1 풀이 여러 묶음 중 어떤 2가지 묶음을 선택하느냐에 따라 전체 비교 횟수가 달라진다. 문제의 예시만 봐도 알 수 있다. 예시를 보면 작은 묶음을 먼저 선택하는게 비교 횟수가 적어지는 것을 알 수 있다. 따라서 전체 묶음에서 가장 작은 2가지 묶음을 선택해서 비교 횟수를 추가한 뒤에 다시 합쳐진 묶음을 전체 묶음에 추가하고 정렬을 해줘야 한다. 묶음을 추가하고 정렬을 해야되는 구조가 우선순위큐와 비슷한 구조이고 우선순위의 경우 삽입 삭제가 O(logN)이므로 빈번하게 삽입삭제가 나타나는 이 문제에서 사용하기 적절하다. 소스코드 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 3..